Salud del Sistema
La página Monitor del Pipeline muestra el estado en vivo del pipeline de procesamiento. Se actualiza automáticamente cada cinco segundos y muestra cuántos registros están esperando en cada etapa, qué tan rápido fluyen los registros, qué lotes están en ejecución actualmente y si alguna etapa tiene mensajes acumulados que necesitan atención. Úsala para verificaciones rápidas de salud y como primera parada cuando una sincronización parece más lenta de lo esperado.
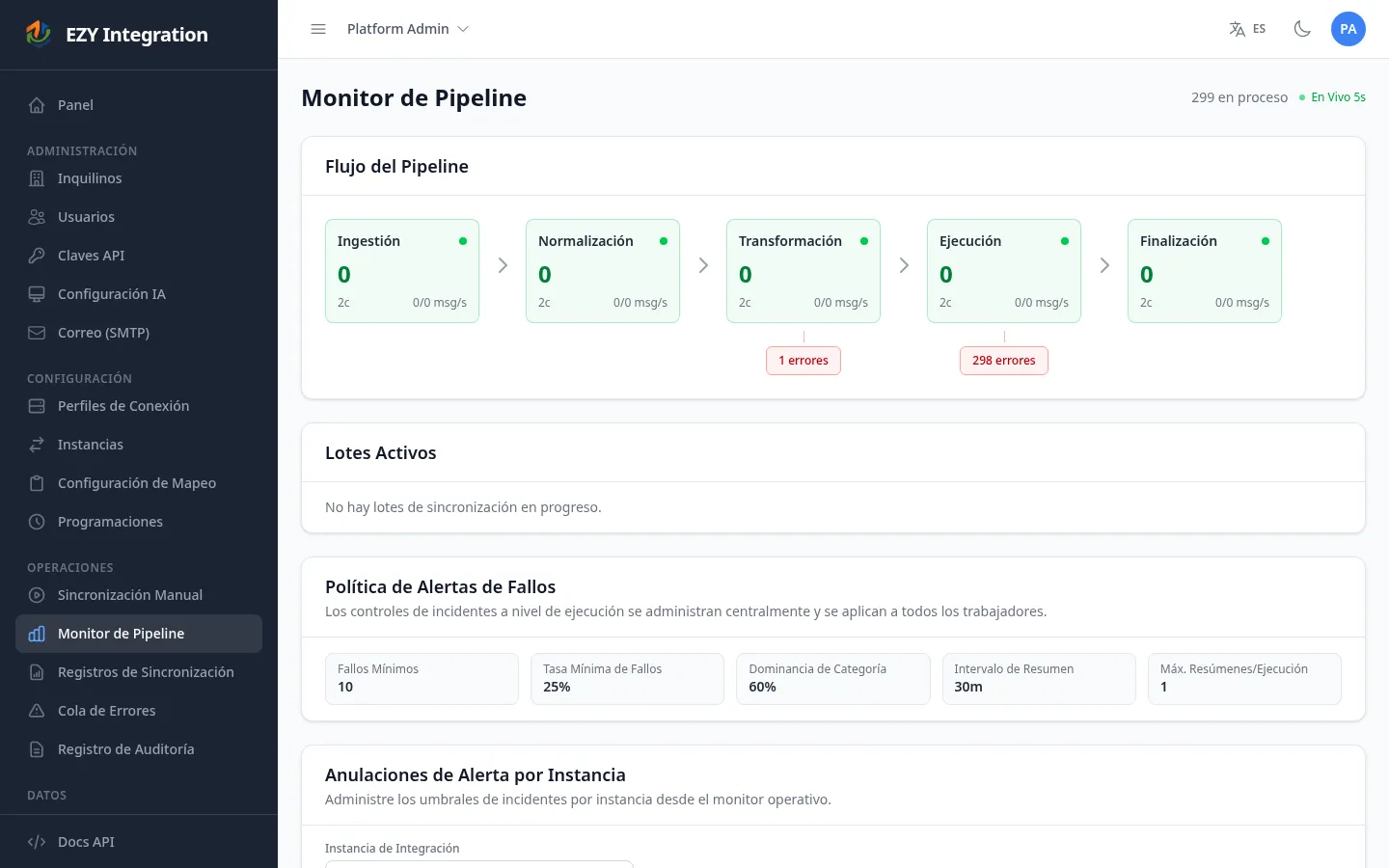
Acceder a la página
Sección titulada «Acceder a la página»En la navegación izquierda, bajo Operaciones, selecciona Monitor del Pipeline.
Un indicador En vivo 5s en el encabezado de la página confirma que la pantalla se actualiza en tiempo real. El encabezado también muestra el número total actual de registros en proceso en todas las etapas.
Leer el flujo del pipeline
Sección titulada «Leer el flujo del pipeline»La tarjeta Flujo del Pipeline muestra una caja por etapa de procesamiento, dispuestas de izquierda a derecha en el orden en que los registros las atraviesan:
graph LR
A[Ingesta] --> B[Normalizar]
B --> C[Transformar]
C --> D[Ejecutar]
D --> E[Finalizar]
D -->|en caso de fallo| F[Error]
Cada caja de etapa muestra:
| Indicador | Significado |
|---|---|
| Nombre de etapa | La etiqueta legible para este paso de procesamiento. |
| Conteo de mensajes | Número de registros que actualmente esperan ser procesados en esta etapa. |
| Punto de estado | Verde cuando el conteo es bajo; se vuelve ámbar o rojo a medida que el conteo crece. |
| Conteo de consumidores | Número de trabajadores activos procesando registros en esta etapa. |
| Rendimiento | Tasa de publicación y tasa de entrega en mensajes por segundo, mostrado como entrada/salida msg/s. |
Debajo de cada caja de etapa, aparece una caja más pequeña de conteo de errores si algún registro ha fallado en esa etapa y está esperando atención. Estos registros no han sido reintentados automáticamente.
Cómo se ve un pipeline saludable
Sección titulada «Cómo se ve un pipeline saludable»- Todas las cajas de etapa muestran un conteo de mensajes bajo o cero.
- Los puntos de estado son verdes.
- Los números de rendimiento son distintos de cero cuando una sincronización está en ejecución.
- Los Lotes Activos muestran lotes en ejecución con progreso avanzando con el tiempo.
- La tabla de Ejecuciones Fallidas Recientes está vacía o muestra un bajo porcentaje de fallos.
Señales de advertencia
Sección titulada «Señales de advertencia»| Señal | Causa probable | Qué hacer |
|---|---|---|
| Una etapa tiene un conteo de mensajes grande y creciente | El procesamiento está atascado en esa etapa — los trabajadores pueden estar detenidos o el sistema de destino es lento | Revisa Registros de Sincronización para ver mensajes de error; escala si los mensajes no se drenan en unos minutos |
| Aparece caja de conteo de errores bajo una etapa | Los registros fallaron en esa etapa y necesitan acción manual | Abre DLQ y Reintento para inspeccionar y reproducir o descartar |
| Todas las cajas de etapa muestran cero consumidores | Los trabajadores no están en ejecución | Contacta a tu administrador del sistema |
| Un lote activo no muestra progreso durante varios minutos | El lote puede estar atascado | Usa la opción Limpiar (solo admin) para cancelar el lote atascado y luego vuelve a activar la ejecución |
| Mensaje “No se puede conectar” en la tarjeta de flujo | El servicio de monitoreo no puede comunicarse con el backend del pipeline | Contacta a tu administrador del sistema |
Lotes activos
Sección titulada «Lotes activos»La tarjeta Lotes Activos lista todos los lotes de sincronización actualmente en progreso. Para cada lote puedes ver:
- El nombre de la instancia de integración y el tipo de entidad que se sincroniza.
- Cómo se activó el lote (programado, manual o cascada de dependencias).
- Tiempo transcurrido desde que inició el lote.
- Una barra de progreso que muestra registros procesados sobre el total, dividida en segmentos verde (éxito), gris (omitido) y rojo (fallido).
- El número de fallos, si los hay.
Cuando un lote está en la fase de extracción y el conteo total de registros aún no se conoce, la barra de progreso pulsa en azul con la etiqueta “Extrayendo…”.
Los administradores pueden cancelar un lote atascado individual usando el botón Limpiar en su tarjeta, o cancelar todos los lotes en ejecución a la vez usando Limpiar Todo. Ambas acciones son irreversibles — los registros pendientes en el lote cancelado se descartan.
Política de alertas por fallos
Sección titulada «Política de alertas por fallos»La tarjeta Política de Alertas por Fallos muestra los umbrales globales que activan una notificación de incidente cuando una ejecución produce demasiados fallos:
| Campo | Descripción |
|---|---|
| Mín. de Fallos | Número mínimo de registros fallidos antes de que se genere un incidente. |
| Mín. de Tasa de Fallos | Porcentaje mínimo de fallos antes de que se genere un incidente. |
| Dominancia de Categoría | Porcentaje mínimo de fallos que deben pertenecer a una categoría de error para que se envíe un resumen. |
| Intervalo de Resumen | Con qué frecuencia (en minutos) el sistema envía un correo de resumen de fallos. |
| Máx. de Resúmenes/Ejecución | Número máximo de correos de resumen enviados por ejecución. |
Estos umbrales se aplican globalmente. Los administradores pueden establecer anulaciones por instancia en la tarjeta Anulaciones de Alertas por Instancia debajo — útil cuando una instancia específica tolera una tasa de fallos más alta que el valor predeterminado del sistema.
Ejecuciones fallidas recientes
Sección titulada «Ejecuciones fallidas recientes»La tabla Ejecuciones Fallidas Recientes muestra las ejecuciones de integración que terminaron con un alto porcentaje de fallos. Para cada ejecución puedes ver el nombre de la instancia, tipo de entidad, estado final, conteo de registros fallidos sobre el total, el porcentaje de fallos y la hora de inicio. Usa esta tabla para el triaje de incidentes cuando necesitas una lista rápida de qué trabajos están fallando sin buscar en los Registros de Sincronización.
Cuándo escalar
Sección titulada «Cuándo escalar»Acciones de autoservicio disponibles desde esta página:
- Reproducir registros fallidos desde la DLQ (ver DLQ y Reintento).
- Limpiar un lote atascado (se requiere rol de administrador).
- Ajustar umbrales de alerta por instancia (se requiere rol de administrador).
Escala a tu administrador del sistema cuando:
- Los trabajadores muestran cero consumidores y no se recuperan después de unos minutos.
- La tarjeta de flujo del pipeline muestra un error de conexión.
- Una cola de etapa continúa creciendo sin drenarse después de reproducir o limpiar.
Páginas relacionadas
Sección titulada «Páginas relacionadas»- Registros de Sincronización — historial de sincronización por registro
- DLQ y Reintento — reproduce o descarta registros fallidos
- Registro de Auditoría — historial de cambios de configuración
- Errores Comunes — patrones de error y resoluciones